| So how to organise all my separate branch L-Systems so that its easy to know which of the turtle strings needs to be drawn without having to sort out the initial string which is organised to how far the branch is from the main stem. So in the right hand column we have all the branch L-Systems. Now we create a new array which is the the length of the draw loop. In the array we store a value which tells use the index value for the right hand array L-systems that are being drawn at any given time. So far as I can see this is all the information that is now needed to | [0] [0] [0] [0] [0, 1, 2] [0, 1, 2] [0, 1, 2] [0, 1, 2, 7, 8, 11, 12] [0, 1, 2, 7, 8, 11, 12] [0, 1, 2, 7, 8, 11, 12, 19, 20, 21, 22, 23, 24, 25, 26] [0, 1, 2, 3, 4, 7, 8, 9, 10, 11, 12, 13, 14, 19, 20, 21, 22, 23, 24, 25, 26] [0, 1, 2, 3, 4, 9, 10, 13, 14] [0, 3, 4, 15, 16, 17, 18] [0, 3, 4, 5, 6, 15, 16, 17, 18] [0, 5, 6] | [0, 0, 0, 'FFFFFFFFFFFFFFX'] [4, 0, 1, '+FFFFFFX'] [4, 0, 2, '-FFFFFFX'] [10, 0, 3, '+FFX'] [10, 0, 4, '-FFX'] [13, 0, 5, '+X'] [13, 0, 6, '-X'] [7, 1, 7, '+FFX'] [7, 1, 8, '-FFX'] [10, 1, 9, '+X'] [10, 1, 10, '-X'] [7, 2, 11, '+FFX'] [7, 2, 12, '-FFX'] [10, 2, 13, '+X'] [10, 2, 14, '-X'] [12, 3, 15, '+X'] [12, 3, 16, '-X'] [12, 4, 17, '+X'] [12, 4, 18, '-X'] [9, 7, 19, '+X'] [9, 7, 20, '-X'] [9, 8, 21, '+X'] [9, 8, 22, '-X'] [9, 11, 23, '+X'] [9, 11, 24, '-X'] [9, 12, 25, '+X'] [9, 12, 26, '-X'] |
|
0 Comments
Right here is a normal L-System string:
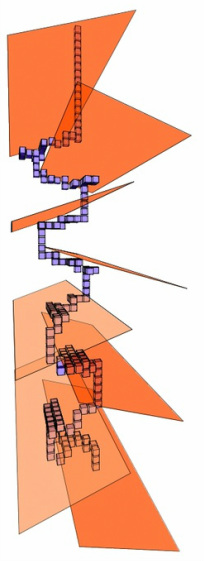
FFFF[+FF[+F[+X][-X]FX][-F[+X][-X]FX]FFF[+X][-X]FX][-FF[+F[+X][-X]FX][-F[+X][-X]FX]FFF[+X][-X]FX]FFFFFF[+F[+X][-X]FX][-F[+X][-X]FX]FFF[+X][-X]FX Now this if we visualise this in term of parent child branching we can visualise it in this manner: FFFF FFFFFF FFF FX [+FF FFF FX][-FF FFF FX] [+F FX][-F FX] [+X][-X] [+F FX][-F FX] [+X][-X] [+F FX][-F FX] [+X][-X] [+X][-X] [+X][-X] [+X][-X] [+X][-X] [+X][-X] [+X][-X] So how does the code work. Well first it scans through the lowest level branch (in this case the main trunk) and extracts the string. In this case it would be [0, -1, 0, 'FFFFFFFFFFFFFFX']. The first number is the when to start its growth (obviously we start the trunk at time 0. Then the second index is what matrix it needs to inherit from, -1 just means no inheritance. The final number is the branch id which is used when inheriting the matrix. Next we calculate the child branch of the previous stem. This will give us [4, 0, 1, '+FFFFFFX'], [4, 0, 2, '-FFFFFFX'], [10, 0, 3, '+FFX'], [10, 0, 4, '-FFX'], [13, 0, 5, '+X'], [13, 0, 6, '-X']. All the first branches will inherit their matrix from the first branch but at different times of the first branch growth. The second child branching returns [7, 1, 7, '+FFX'], [7, 1, 8, '-FFX'], [10, 1, 9, '+X'], [7, 2, 11, '+FFX'],[10, 2, 13, '+X'], [10, 2, 14, '-X'], [12, 3, 15, '+X'], [12, 3, 16, '-X'], [12, 4, 17, '+X'], [12, 4, 18, '-X'], [9, 7, 19, '+X'], [9, 7, 20, '-X'], [9, 8, 21, '+X'], [9, 8, 22, '-X']. Now we can see we are inheriting from the previous parent branches created. In this example the final branches are as follows, [9, 11, 23, '+X'], [9, 11, 24, '-X'], [9, 12, 25, '+X'], [9, 12, 26, '-X'].Well this is all currently looking great so now lets do it in C++.  Figure 1. Figure 1. One big problem with the way an L-System string works is that although it describes the plant form at a specific generation the construction of an L-System does not follow the way a tree would grow. Figure 1 shows the way in which the tree is constructed. At a branching sequence the entire branch is constructed before returning to the branching point and continuing the tree. If I want to simulate plant competition I need the branches to grow at the same time so that the tree grows from the base to the tip. My current line of investigation is to treat each branching point as a spawning point for new L-system. The information I need to gain from the axiom is therefore an index of when to start growing each L-System and also which matrix it needs to inherit from.
I have managed to implement the start of light affecting the L-System. Figure 1 shows a trees growth growth being affected by light availability. Each of the trees are using exactly the same L-System rules and all random variation to variables disabled. On the left is a tree grown in full light. In the middle the tree is grown underneath an object. To the right the tree is grown next to a wall. 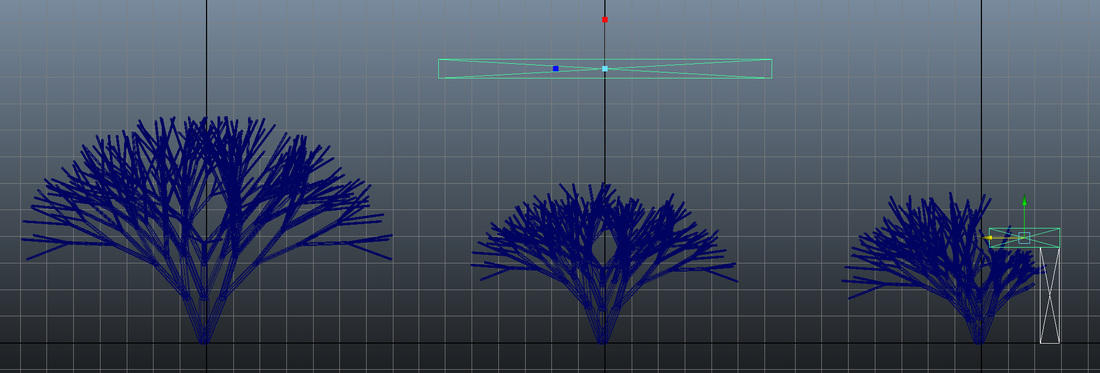 Figure 1 shows the effect of shade on tree growth The method for calculating the light has already been outlined in a previous post ( Calculating voxel light intensity ). The way this has been implemented is that when a branch growth call ('F') is reached in the light reaching that point is calculated. This is done by creating a spherical scattering of points which are used as light ray vectors. This is done using Marsaglias scattering method ( N-Rooks will not work, solution is to use Marsaglias' scatter method ) and calculating the fraction of rays that hit a collision object. The result is then used to modify the growth of the current branch. Currently the alteration of the branch is linearly related to the light intensity. I will want to see if I can make this a bit more scientific but for now that will do.
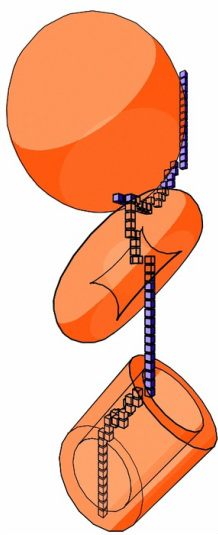
The current implementation has a couple of Maya crashing features helpfully added. Currently if the tree grows outside the voxel space the programme crashes because an index exceeding the length in the voxelStatus array is called. The other problem can be seen in Figure 1 on the right image where there is still a branch that grows through the collision object. This is to do with the number of sub-steps calculated to detect whether a branch will growth through an occupied voxel.  Figure 1. Ideal L-System shape Figure 1. Ideal L-System shape I have combined the voxel collision with my L-System using the Maya C++ Api. Figure 1 shows the ideal shape of a tree based on a set of rules. However, in Figure 2 uses the same rules but the trees final shape is restricted by the two spheres. Figure 3 shows the same tree but with the spheres hidden. Now I will briefly outline the code used to implement this. First the voxels occupied by the collision objects are calculated using the same methodology as I discussed in an earlier post, the only difference is that it is done in C++. Next the L-System is drawn. Before a draw call, 'F', is calculate the code checks to see whether the proposed  Figure 2. L-System with voxel collision objects Figure 2. L-System with voxel collision objects branch will growth through an occupied voxel. The vector of the branch growth and the current position is extracted from the transformation matrix. The number of voxel lengths that go into the magnitude of growth is calculated. This number is then increased by a factor of 20. What this means is that if the branch growth magnitude is 2.0f and the voxel size is 1.0f then the number of steps along the branch will be 2.0 / (1.0 * 0.05 ) = 40 steps. Now all that remains is to incrementally step along the proposed branch and check if each point hits an occupied voxel. The final thing is to have a check that the no further actions are  Figure 3. L-System with collision objects hidden Figure 3. L-System with collision objects hidden taken until the next branch call ']' is reached. Because there can be several nested branch calls on the current branch this needs to be accounted for.
The method is still very basic. First, currently the method only stops growth. In fact I want to have the tree grows growth to be changed by a collision object causing it to grow around the object. Secondly The as the tree grows it does not change the voxel from empty to occupied shape. I will implement these features next. One final thing I can now easily add is calculating the light intensity at each growth call. This can then be used to alter the magnitude of growth which will create a more believable result as we would expect the tree to grow less in darker areas. Disclaimer: I am more than likely wrong about some or all of what I am saying but it appears to be working.
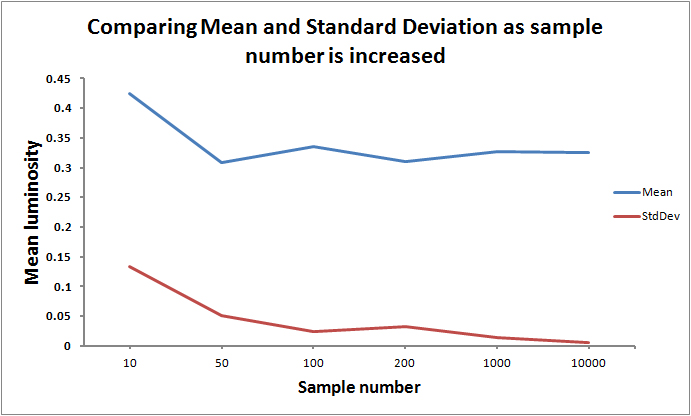
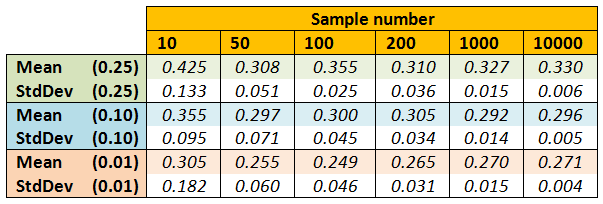
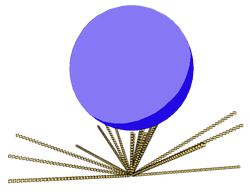 Using the voxel occupation and spherical sampling I have now implemented a methods for estimating voxel illumination. The method uses the sample points created from the spherical scattering. These points are used as vectors. Each vector is then moved along and for each increment its position is checked to determine whether it is in an occupied voxel or not. This gives us a fraction of the number of rays that hit an occupied voxel over the number of total rays emitted. This fraction indicates the light intensity in the voxel. Increasing the sampling density will obviously make the estimation more accurate and so I compared the mean value and standard deviation of results at various sampling numbers. The voxel size was 0.25. The test was run 20 times for each increment. The results are shown in Figure 1. To see what effect changing the size of the voxels had on the results the test was repeated and the size set to 0.1 and 0.01. The results are shown in Figure 2.
 Figure 1. N-Rooks scatter results Figure 1. N-Rooks scatter results I discovered that using N-Rooks sampling was not going to work. To explain why firstly I will describe what I need to do. The problem is to send rays towards a sky dome to determine the light intensity in a voxel. How this will be determined will be described later once I have it working. Anyway my idea was to create 2D N-Rooks sample above the voxel position and then derive my normalised vectors from these points. The results of this method are shown in Figure 1. Clearly there are are a number of problems.
 To solution, simply find a proper methods. I chose to use Marsaglias' methods[1]. The results are visible in Figure 2. This solved all my issues from the initial idea. The method is to generate to numbers v1 and v2 between [-1, 1]. If you only want to sample top half of the sphere, as I do then change the random range of v2 to [0, 1]. Calculate S = (v1 * v1) + (v2 * v2) and ensure that S >= 1. The we can calculate the positions as follows: x = 2 * v1 sqrt( 1 - (v1 * v1) - (v2 * v2)) y = 2 * v2 sqrt( 1 - (v1 * v1) - (v2 * v2)) z = 1 - 2((v1 * v1) - (v2 * v2)) 1. G, Marsaglia. (1972). Choosing a point from the surface of a sphere. The Annals of Mathematical Statistics. 43, 2. p 645 - 646
|
AuthorWrite something about yourself. No need to be fancy, just an overview. Archives
March 2014
Categories |

 RSS Feed
RSS Feed
